Если у вас SQL версия 1с77, то в файле 1Cv7.DDS хранится структура-описание базы данных
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
#=============================================================================== #==TABLE no 11 : Справочник БанковскиеСчета # Name |Descr |SQLTableNam|RecordLock T=SC1504 |Справочник БанковскиеСчета |SC1504 |R #-----Fields------- # Name |Descr |Type|Length|Precision F=ROW_ID |Row ID |I |0 |0 F=ID |ID object |C |9 |0 F=CODE |object code |C |5 |0 F=DESCR |object description |C |25 |0 F=PARENTEXT |Parent in other tabl|C |9 |0 F=ISMARK |Object is Marked for|L |0 |0 F=VERSTAMP |Version stamp |I |0 |0 F=SP1498 |(P)Номер |C |20 |0 F=SP1499 |(P)БанкОрганизации |C |9 |0 F=SP1500 |(P)БанкДляРасчетов |C |9 |0 F=SP1501 |(P)ДатаОткрытияСчета|D |0 |0 F=SP1502 |(P)ДатаЗакрытияСчета|D |0 |0 #----Indexes------ # Name |Descr |Unique|Indexed fields |Type I=PK_SC1504 |Row Id |1 |ROW_ID |1 I=IDD |of ID |1 |ID |0 I=PCODE |of PARENT and |1 |PARENTEXT,CODE,ROW_ID |0 I=PDESCR |of PARENT and |1 |PARENTEXT,DESCR,ROW_ID |0 I=CODE |of CODE |1 |CODE,ROW_ID |0 I=DESCR |of DESCR |1 |DESCR,ROW_ID |0 I=VI1498 |VI1498 |1 |SP1498,ROW_ID |0 I=VIP1498 |VIP1498 |1 |PARENTEXT,SP1498,ROW_ID |0 # |
Вот например как описывается справочник БанковскиеСчета. Макроподстановки в «прямых запросах» так и работают, находят название, и подставляют таблицу.
В данный момент нам интересны индексы. Индексы используются для ускорения поиска в больших таблицах. Почему именно в больших? Да потому что запись-то страдает… нужно же еще и индекс обновить.
Вот реальный пример. Мне потребовалось искать документ по его номеру
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#==TABLE no 3 : Журналы # Name |Descr |SQLTableNam|RecordLock T=1SJOURN |Журналы |_1SJOURN |R #-----Fields------- # Name |Descr |Type|Length|Precision F=ROW_ID |Row ID |I |0 |0 F=IDJOURNAL |ID of Journal |I |0 |0 F=IDDOC |ID Document |C |9 |0 F=IDDOCDEF |ID Def Document |I |0 |0 F=APPCODE |App code |S |0 |0 F=DATE_TIME_IDDOC |Date+Time+IDDoc |C |23 |0 F=DNPREFIX |Prefix Document No |C |18 |0 <strong>F=DOCNO |Document No |C |15 |0 </strong> |
, использую запрос вида like, но вот незадача, выполнение запроса 1,5 секунды(!!!). Когда дополз до индекса, понял что подходящего индекса просто нет, поэтому тупо в лоб перебирается вся таблица…. (т.к. она же не отсортирована по номеру).
В общем создал индекс с данным столбцом
Через MS SQL Server Managment Studio (MS SSMS)
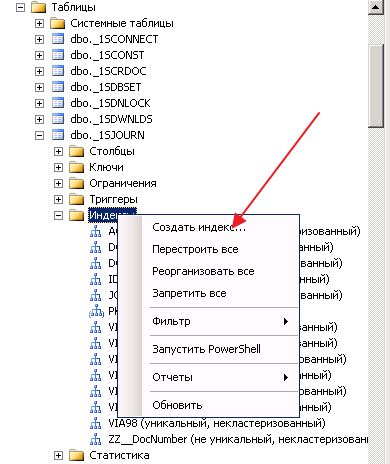

Или же запросом
|
1 2 3 4 5 6 7 8 9 10 11 12 |
USE [TEST1] GO BEGIN -- Таблица Журнал -- Индекс "НомерДок" IF NOT EXISTS(SELECT * FROM sys.indexes WHERE object_id = object_id('_1SJOURN') AND NAME ='ZZ__DocNumber') CREATE NONCLUSTERED INDEX ZZ__DocNumber ON [dbo].[_1SJOURN] ( DOCNO ) END |
После создания индекса, запрос по номеру документа с 1,5 секунды стал выполняться 0,03 сек.
Но рано радоваться… У вас все получится если вы создавали индекс на запущенном предприятии, в ином случае при запуске в режиме не монопольно, вы получите ошибку нарушение целостности таблицы (Индекс есть, а описания нет….) Если зайдете монопольно, предприятие вообще грохнет индекс 😀
Решение есть (не окончательное!!)
Добавляете в файл 1Cv7.DDS описание нового индекса
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
#==TABLE no 3 : Журналы # Name |Descr |SQLTableNam|RecordLock T=1SJOURN |Журналы |_1SJOURN |R #-----Fields------- # Name |Descr |Type|Length|Precision F=ROW_ID |Row ID |I |0 |0 F=IDJOURNAL |ID of Journal |I |0 |0 F=IDDOC |ID Document |C |9 |0 F=IDDOCDEF |ID Def Document |I |0 |0 F=APPCODE |App code |S |0 |0 F=DATE_TIME_IDDOC |Date+Time+IDDoc |C |23 |0 F=DNPREFIX |Prefix Document No |C |18 |0 F=DOCNO |Document No |C |15 |0 F=CLOSED |Flag document is clo|Y |0 |0 F=ISMARK |Doc is Marked for De|L |0 |0 F=ACTCNT |Action counter |I |0 |0 F=VERSTAMP |Version stamp |I |0 |0 F=RF216 |Reg Action Flag |L |0 |0 F=RF582 |Reg Action Flag |L |0 |0 F=RF560 |Reg Action Flag |L |0 |0 F=RF569 |Reg Action Flag |L |0 |0 F=RF246 |Reg Action Flag |L |0 |0 F=RF305 |Reg Action Flag |L |0 |0 F=RF262 |Reg Action Flag |L |0 |0 F=RF813 |Reg Action Flag |L |0 |0 F=RF980 |Reg Action Flag |L |0 |0 F=RF1020 |Reg Action Flag |L |0 |0 F=RF1395 |Reg Action Flag |L |0 |0 F=RF1408 |Reg Action Flag |L |0 |0 F=RF1554 |Reg Action Flag |L |0 |0 F=RF1914 |Reg Action Flag |L |0 |0 F=RF1942 |Reg Action Flag |L |0 |0 F=RF2212 |Reg Action Flag |L |0 |0 F=RF2419 |Reg Action Flag |L |0 |0 F=RF2995 |Reg Action Flag |L |0 |0 F=RF3935 |Reg Action Flag |L |0 |0 F=SP98 |(P)Фирма |C |9 |0 F=SP658 |(P)Точка |C |9 |0 F=SP289 |(P)ТипУчета |C |9 |0 F=SP1212 |(P)Автор |C |9 |0 F=SP2254 |(P)мбИдентификатор |C |50 |0 F=DS284 |Flag document in seq|Y |0 |0 F=DS581 |Flag document in seq|Y |0 |0 #----Indexes------ # Name |Descr |Unique|Indexed fields |Type I=PK__1SJOURN |ROW_ID |1 |ROW_ID |1 I=IDDOC |Id Doc |1 |IDDOC |0 I=ACDATETIME |Date+Time+ID |1 |DATE_TIME_IDDOC |0 I=DOCNO |Prefix+No |1 |DNPREFIX,DOCNO,ROW_ID |0 I=DOCTYPE |Type+Date+Time|1 |IDDOCDEF,DATE_TIME_IDDOC |0 I=JOURNAL |Journal+Date+T|1 |IDJOURNAL,DATE_TIME_IDDOC |0 I=VIA98 |VIA98 |1 |SP98,DATE_TIME_IDDOC |0 I=VIA658 |VIA658 |1 |SP658,DATE_TIME_IDDOC |0 I=VIA289 |VIA289 |1 |SP289,DATE_TIME_IDDOC |0 I=VIA1212 |VIA1212 |1 |SP1212,DATE_TIME_IDDOC |0 I=VIA2254 |VIA2254 |1 |SP2254,DATE_TIME_IDDOC |0 I=VIA284 |VIA284 |0 |DS284,DATE_TIME_IDDOC |0 I=VIA581 |VIA581 |0 |DS581,DATE_TIME_IDDOC |0 <strong>#Доп. индекс Журнал I=ZZ__DocNumber |Номер документа |0 |DOCNO |0 </strong> |
Немного опишу:
| Колонка | Описание |
| I=ZZ__DocNumber | название индекса после «=» |
| Номер документа | описание, можно написать все что угодно, но постарайтесь немного |
| 0 | Уникальность индекса (соответствует галке MS SQL) |
| DOCNO | столбцы из чего состоит индекс (описывайте ровно также, иначе верификацию не пройдете) |
| 0 | кластеризованный/не кластированный индекс. У вас будет некластеризованные индексы, т.к. второй создать нельзя |
После сохранении, 1с будет считать что все хорошо. Будьте внимательны, индексы описывайте в конце. Я к примеру по данной таблице поставил индекс первым, в итоге поиск документа в журнале был по колонкам моего индекса. Долго понять не мог почему ошибка выскакивает, с профайлером разобрался.
После сохранении конфигурации вам (в момент реструктуризации, когда добавится/удалится какой либо объект), ваши данные слетят и придется заново добавлять эти изменения.
Как это автоматизировать, напишу позже в новой заметке.